CSC 217 Lab 10 Implement and Test Custom LinkedList
The design of the faculty directory functionality calls for a custom implementation of a linked list that doesn’t allow for null elements or duplicate elements as defined by the equals() method.
You will use test driven development to implement the custom LinkedList. Each section below describes the methods that you will be implementing.
LinkedList will inherit from java.util.AbstractSequentialList. AbstractSequentialList provides functionality for all standard list methods by implementing them in terms of an Iterator. However, the details about how the Iterator works is left to the author of the extending class - us! For the methods that LinkedList inherits from AbstractSequentialList to work, we have to create LinkedListIterator, which implements the ListIterator interface.
Additionally, we need to provide some custom behavior to LinkedList.add() and LinkedList.set(). The implementation of these methods from AbstractSequentialList allows duplicate values. However, we don’t want to allow duplicate values, so we need to override the functionality of LinkedList.add() and LinkedList.set() to check for duplicates. If no duplicate is found, then we can delegate to the parent (i.e., super.add() and super.set()).
Create LinkedList Class
Create LinkedList in the src/ folder of the edu.ncsu.csc216.pack_scheduler.util package.
LinkedList should extend java.util.AbstractSequentialList and should have a generic type parameter, E.
Create LinkedListTest Class
Create LinkedListTest in the test/ folder of the edu.ncsu.csc216.pack_scheduler.util package.
Since the LinkedListTest expected functionality is identical to ArrayList’s functionality, you should start from the ArrayList tests. Copy those into LinkedListTest.
When testing, you should work with a list of Strings. Those will be easier to test that more complex objects like Facultys.
Implement ListNode
ListNode is an inner class of LinkedList. Add the class after the last method but before closing the LinkedList curly brace. The ListNode class header should look like the following:
private class ListNode { ... }
Note that ListNode’s constructor has no generic type in this implementation. ListNode will use LinkedList’s generic type.
ListNode has three public fields. Add the fields to the ListNode class:
data: typeE- the data in the nodenext: typeListNode- the next node in the listprev: typeListNode- the previous node in the list
ListNode has two constructors. Add the constructors to the ListNode class. They should assign the parameter to the associated fields:
ListNode(E data)ListNode(E data, ListNode prev, ListNode next)
Create LinkedListIterator
AbstractSequentialList provides functionality for all standard list methods by implementing them in terms of an Iterator. That means to create a concrete implementation of AbstractSequentialList, you need to implement the ListIterator interface. Create an inner class named LinkedListIterator that implements the ListIterator interface. The LinkedListIterator class header should look like the following:
private class LinkedListIterator implements ListIterator<E> { ... }
LinkedListIterator has five fields:
previous: represents theListNodethat would be returned on a call toprevious()next: represents theListNodethat would be returned on a call tonext()previousIndex: the index that would be returned on a call topreviousIndex()nextIndex: the index that would be returned on a call tonextIndex()lastRetrieved: represents theListNodethat was returned on the last call to eitherprevious()ornext()or null if a call toprevious()ornext()was not the last call on theListIterator.
In addition to the eight methods from ListIterator that you must override (and will implement in the following steps), LinkedListIterator has a constructor that accepts an index to position the iterator. For now, stub out the constructor. You’ll implement it later.
public LinkedListIterator(int index) {
//TODO implement later
}
The LinkedListIterator is an object that represents the current location of the LinkedListIterator in the LinkedList. Because you are working with a doubly linked list, the LinkedListIterator can move forward or backward in the list during traversal. That means that the current location of the LinkedListIterator is always between TWO ListNodes. To simplify the implementation of the LinkedListIterator methods, the LinkedList class will always have two ListNodes with null data. These nodes represent the idea of index -1 and index size in our list. By having these null data ListNodes the LinkedListIterator is always between two ListNodes even when the LinkedListIterator is at the front of the list or back of the list. The model is shown in the figure below.
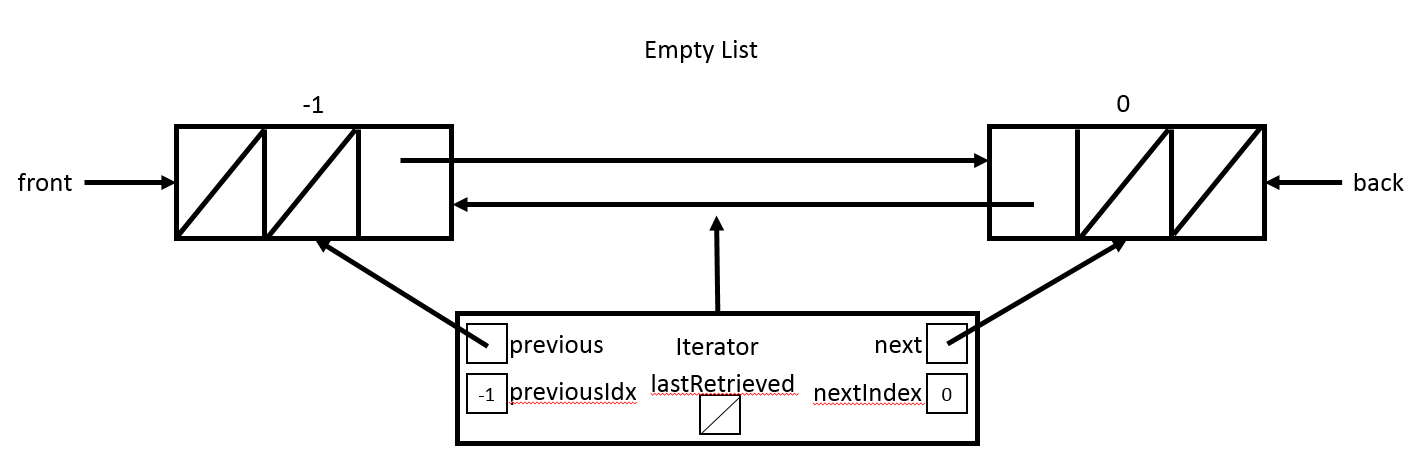
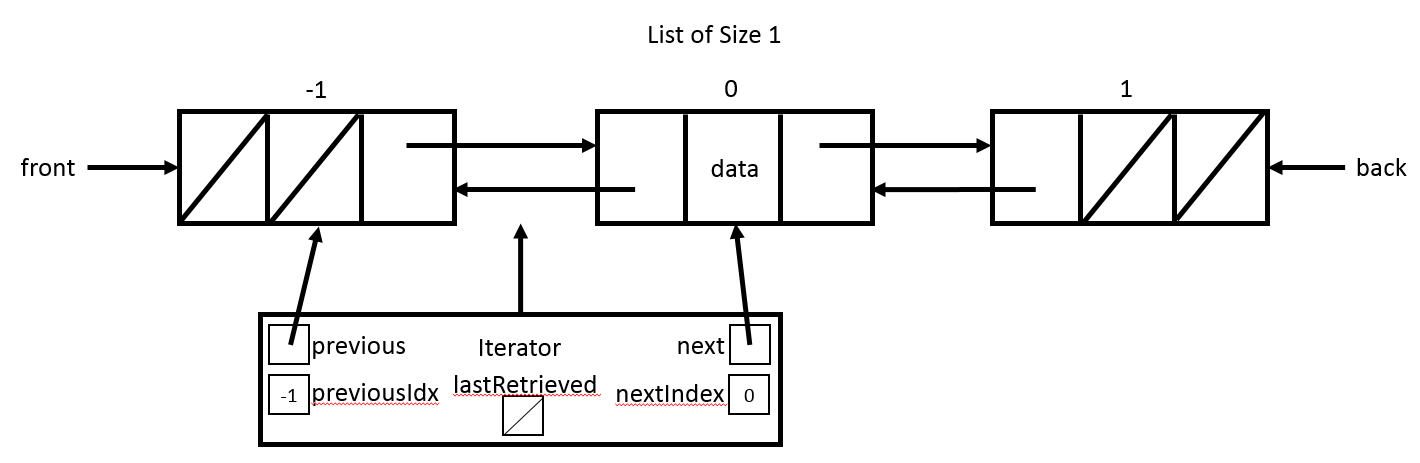
Implement LinkedList State
LinkedList has the following state:
front: aListNodeback: aListNodesize: the size of the list
Implement LinkedList.LinkedList()
The constructor of LinkedList should initialize the state. To fit the model where a LinkedListIterator should always be between two ListNodes, you need to create two ListNodes with null data that represent the idea of nodes that are out of bounds at indexes -1 and size so that your empty list looks like:
That means the constructor of LinkedList should do the following:
- Create a
ListNodewithnulldata thatfrontpoints to. - Create a
ListNodewithnulldata thatbackpoints to. - Have
front’snextpoint toback - Have
back’sprevpoint tofront - Initialize
sizeto 0.
Implement LinkedList.size()
One of the two abstract methods in AbstractSequentialList is size(). Implement size() to return the size field.
Implement LinkedList.listIterator()
The other abstract method in AbstractSequentialList is listIterator(). The method returns a ListIterator<E> that is positioned such that a call to ListIterator.next() will return the element at given index (as per the AbstractSequentialList API. All LinkedList.listIterator() does is construct a LinkedListIterator object. When constructing the LinkedListIterator object, you don’t need the generic type on the constructor because the generic type is handled by extending ListIterator<E>!
Implement LinkedListIterator.LinkedListIterator()
The constructor for LinkedListIterator recieves an index for positioning the LinkedListIterator in the list. That means the constructor needs to traverse to the appropriate location, which is between index-1 and index. That means you satisfy the instructions in AbstractSequentialList that the value at index is what is returned on a call to next(). To implement LinkedIntListIterator(), do the following:
- Check the
indexto ensure that it’s within bounds of the list. If not, throw anIndexOutOfBoundsExceptionthat will propagate through theLinkedList.listIteartor()method. - If the
indexis within bounds, iterate through the list so that thepreviousListNodepoints to theListNodeatindex-1and thenextListNodepoints to theListNodeatindex. - Update the
previousIndexandnextIndexfields. lastRetrievedshould be null.
By implementing the padding of a lead and trailing ListNode with null data, you ensure that previous points to the ListNode with null data when the LinkedListIterator is at the front of the list and that next points to the ListNode with null data when the LinkedListIterator is at the end of the list.
Implement LinkedListIterator.has*() and LinkedListIterator.*Index() Methods
The LinkedListIterator.has*() method return true if there is a next or previous node in the list (i.e., a ListNode where the data is not null). Implement the has*() methods using the API for guidance.
The LinkedListIterator.*Index() methods return the index of the next or previous node in the list. Implement the *Index() methods using the API for guidance.
Start running your tests and ensure that the the tests that don’t involve adding, removing, or setting pass.
Implement LinkedListIterator.next() and LinkedListIterator.previous() Methods
The LinkedListIterator.next() and LinkedListIterator.previous() methods return the element in the next or previous ListNode. If the next or previous ListNode has null data, you should throw a NoSuchElementException. Remember, the next() and previous() methods will move forward or backward through the list before returning the value but after retrieving the value to return.
The next() and previous() methods should set lastRetrieved to the ListNode that contains the returned value. This will be used in the methods for modifying the list as a flag for if an operation can happen.
Run your tests to ensure no regressions.
Implement LinkedListIterator.add(E)
Override and implement the LinkedListIterator.add(E) method. As per the ListIterator API, the add() method will insert the element before the element that would be returned by next(). Don’t forget to increment size. The API states:
Inserts the specified element into the list (optional operation). The element is inserted immediately before the element that would be
returned by next(), if any, and after the element that would be returned by previous(), if any. (If the list contains no elements, the
new element becomes the sole element on the list.) The new element is inserted before the implicit cursor: a subsequent call to next
would be unaffected, and a subsequent call to previous would return the new element. (This call increases by one the value that would
be returned by a call to nextIndex or previousIndex.)
When implementing this method, do not allow null objects to be inserted. Those are special values for our leading and trailing ListNodes. If the element to add is null, the method should throw a NullPointerException.
After the add() method is done, lastRetrieved should be set to null. lastRetrieved should only have a value after a call to next() or previous().
After implementing LinkedListIterator.add(), your LinkedList.add() method should pass for everything except duplicate values and LinkedList.get() test should pass.
Override LinkedList.add(int, E)
Checking for duplicate values in LinkedListIterator.add() isn’t possible. The LinkedListIterator is already in position to add. Therefore, you have to override LinkedList.add(int, E) to add a check for a duplicate value.
Put your cursor in the editor between the LinkedList.size() and LinkedList.listIterator() methods. Then right click and select Source > Override/Implement Methods. Select AbstractSequentialList<E>.add(int, E).
If the element to add is a duplicate of an element already in the list as determined by the LinkedList.contains() method, the method should throw an IllegalArgumentException.
After overriding and implementing LinkedList.add(int, E), make sure your LinkedList.add() method passes.
Implement LinkedListIterator.set(E)
Override and implement the LinkedListIterator.set(E) method. As per the ListIterator API, the set() method will modify the element returned by the last call to previous() or next(). The API states:
Replaces the last element returned by next() or previous() with the specified element (optional operation). This call can be made
only if neither remove() nor add(E) have been called after the last call to next or previous.
If lastRetrieved is null, meaning that remove() or add(E) was the last call on the list or there has not been a call to next() or previous(), an IllegalStateException should be thrown.
When implementing this method, do not allow null objects to be set. Those are special values for the leading and trailing ListNodes. If the element to set is null, the method should throw a NullPointerException.
After implementing LinkedListIterator.set(), your LinkedList.set() method should pass for everything except duplicate values.
Override LinkedList.set(int, E)
Checking for duplicate values in LinkedListIterator.set() isn’t possible. The LinkedListIterator is already in position to set. Therefore, you must override LinkedList.set(int, E) to add a check for a duplicate value.
Put your cursor in the editor between the LinkedList.size() and LinkedList.listIterator() methods. Then right click and select Source > Override/Implement Methods. Select AbstractSequentialList<E>.set(int, E).
If the element to set is a duplicate of an element already in the list as determined by the LinkedList.contains() method, the method should throw an IllegalArgumentException.
After overriding and implementing LinkedList.set(int, E), make sure your LinkedList.set() tests pass.
Implement LinkedListIterator.remove()
Override and implement the LinkedListIterator.remove() method. As per the ListIterator API, the remove() method will remove the element returned by the last call to previous() or next(). The API states:
Removes from the list the last element that was returned by next() or previous() (optional operation). This call can only be made
once per call to next or previous. It can be made only if add(E) has not been called after the last call to next or previous.
If lastRetrieved is null, meaning that remove() or add(E) was the last call on the list or there has not been a call to next() or previous(), an IllegalStateException should be thrown.
Otherwise, remove the lastRetrieved ListNode and decrement the size.
After you finish implementing LinkedListIterator.remove(), all tests should pass! If not, debug your implementation.
Javadoc your Code
Javadoc the LinkedList class, state, and methods. For overridden methods remove the green comments and Javadoc them to describe how the methods work in LinkedList. Do NOT delete the @Override annotation.
Run CheckStyle to ensure that your Javadoc has all elements.
Push to GitHub
Push your PackScheduler project to GitHub
- Add the unstaged changes to the index.
- Commit and push changes. Remember to use a meaningful commit message describing how you have changed the code.
Reminder: Staging and Pushing to GitHub
GitHub Resources:
Check Jenkins
Ensure that your Jenkins job is reflecting the results that you expect for the level of completion of your lab assignment.
Reminder: Interpreting Jenkins
Check the following items on Jenkins for your last build and use the results to estimate your grade: